
영속성 컨텍스트의 기능 중 Lazy loading, Eager loading에 대해 공부하다보니 N + 1문제를 접했다. JPA를 쓰다 보면 N + 1 문제를 흔히 접할 수 있고, 면접의 질문으로도 많이 나온다고 한다. N + 1문제에 대해 알아보자
N + 1 문제란?
N + 1문제는 엔티티의 연관관계를 통해 다른 엔티티를 조회할 때, 조회된 데이터 개수(N)만큼 연관관계의 조회 쿼리가 추가로 발생하는 현상이다. 예를 들어, 블로그 게시글과 댓글이 있는 경우, 게시글 목록을 조회한 후(1번의 쿼리) 각 게시글마다 댓글을 조회하기 위한 추가 쿼리(N번의 쿼리)가 발생할 수 있다.
// 엔티티 관계 설정
@Entity
public class Post {
@Id
private Long id;
private String title;
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Comment> comments;
// getters and setters
}
@Entity
public class Comment {
@Id
private Long id;
private String content;
@ManyToOne
private Post post;
// getters and setters
}
// n+1 문제 발생 코드
List<Post> posts = postRepository.findAll(); // 1번의 쿼리
for (Post post : posts) {
List<Comment> comments = post.getComments(); // n번의 추가 쿼리 발생
System.out.println("게시글: " + post.getTitle() + ", 댓글 수: " + comments.size());
}
`findAll()`의 글로벌 패치 전략에 따른 N + 1 문제 상황
Eager loading(즉시 로딩)
FetchType.EAGER로 설정하면, JPA는 엔티티를 조회할 때 연관 엔티티도 함께 로딩하도록 작업한다.
@Entity
public class Post {
@Id
private Long id;
@OneToMany(mappedBy = "post", fetch = FetchType.EAGER)
private List<Comment> comments;
}엔티티가 다음과 같다면 N + 1문제가 발생한다.
- `postRepository.findAll()`로 모든 게시물 조회(1번 쿼리)
- 각 게시글마다 댓글을 즉시 로딩하기 위한 추가 쿼리 발생(N번 쿼리)
SELECT * FROM post; -- 1번
SELECT * FROM comment WHERE post_id = 1;
SELECT * FROM comment WHERE post_id = 2;
SELECT * FROM comment WHERE post_id = 3;
SELECT * FROM comment WHERE post_id = 4;
-- N번 반복 (각 포스트 로딩 시점에 즉시 실행)
N + 1이 발생하는 원인
이 때, N + 1이 발생하는 가장 중요한 원인은 JPQL이 글로벌 패치 전략을 고려하지 않고 쿼리를 실행하기 때문이다.
JPQL이 즉시 로딩을 고려했다면, 아래 SQL문과 같이 모든 게시글을 조회할 때 조인을 통해 조회한 게시글의 모든 댓글도 조회할 수 있어야 한다.
SELECT p.*, c.*
FROM post p
LEFT JOIN comment c ON p.id = c.post_id하지만 실제 동작과정에선 ` SELECT * FROM post`가 먼저 실행되고 결과 엔티티들이 로드될 때, JPA는 글로벌 패치 전략을 확인한다. 그 후, EAGER로 설정된 연관관계를 발견하면, 해당 엔티티마다 추가 쿼리를 실행한다.
findAll() 호출
└─> JPQL 생성: "select p from Post p"
└─> SQL 변환: "SELECT * FROM post"
└─> 결과 처리:
├─> Post 엔티티 #1 로드
│ └─> EAGER 전략 확인: comments 컬렉션 즉시 로드 필요
│ └─> 추가 쿼리: "SELECT * FROM comment WHERE post_id = 1"
├─> Post 엔티티 #2 로드
│ └─> EAGER 전략 확인: comments 컬렉션 즉시 로드 필요
│ └─> 추가 쿼리: "SELECT * FROM comment WHERE post_id = 2"
└─> ... (Post 엔티티 개수만큼 반복)
Lazy loading(지연 로딩)
FetchType.LAZY로 설정하면, JPA는 엔티티를 조회할 때 연관 엔티티를 즉시 로딩하지 않고, 실제로 접근할 때까지 로딩을 지연시킨다.
@Entity
public class Post {
@Id
private Long id;
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Comment> comments;
}엔티티가 다음과 같다면, `postRepository.findAll()`에서는(1번 쿼리) N + 1문제가 발생하지 않는다. `comments` 컬레션이 프록시 객체로만 초기화되어있고 실제 데이터는 로드되지 않았기 때문이다.
하지만, 프록시 객체에 접근할 때 추가 쿼리가 발생한다.(N번 쿼리)
// 이 시점에는 N+1 문제 없음
List<Post> posts = postRepository.findAll();
// 이 루프에서 N+1 문제 발생!
for (Post post : posts) {
System.out.println("게시글 제목: " + post.getTitle());
System.out.println("댓글 수: " + post.getComments().size()); // 여기서 추가 쿼리 발생
}위 코드 실행 시 다음과 같은 N개의 추가 쿼리가 실행된다.
SELECT * FROM comment WHERE post_id = 1;
SELECT * FROM comment WHERE post_id = 2;
...
SELECT * FROM comment WHERE post_id = N;
지연 로딩에서는 조건부로 N + 1문제가 발생한다.
연관 엔티티에 실제로 접근할 때만 문제가 발생하고 접근하지 않으면 추가 쿼리가 발생하지 않는다. (EAGER과의 차이점)
N + 1문제의 해결 방법
N + 1문제에는 3가지정도의 해결 방법이 있다
- Join Fetch
- EntityGraph
- BatchSize
Join Fetch
Join Fetch는 JPA에서 제공하는 기능으로 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능이다.
public interface PostRepository extends JpaRepository<Post, Long> {
// 게시글과 연관된 댓글을 함께 조회
@Query("SELECT p FROM Post p JOIN FETCH p.comments")
List<Post> findAllWithPost();
}
EntityGraph
`@EntityGraph`는 쿼리가 간단하고, 재사용성이 중요할 때 Join Fetch 대신 사용할 수 있다.
public interface PostRepository extends JpaRepository<Post, Long> {
@EntityGraph(attributePaths = {"comments"})
List<Post> findAll();
}💡 Join Fetch vs EntityGraph
Join Fetch는 언제 사용할까?
1. 복잡한 조건이 필요할 때 사용한다. where절에 여러 조건이 필요하거나 join on 절에 추가 조건이 필요한 경우 사용한다.
2. order by, group by 등 정렬이나 그룹핑이 필요할 때 사용한다.
EntityGraph는 언제 사용할까?
1. 코드를 간결하게 작성할 때 사용한다.
2. 동일한 엔티티 로딩 패턴이 반복되거나 일관된 로딩 전략이 필요해 코드 재사용성이 중요할 때 사용한다.
Join fetch를 사용할 때 주의해야할 케이스 2 가지
1. Pagination
Pagination은 대량의 데이터를 여러 페이지로 나눠 표시하는 기법이다. JPA에서 page처리를 할 때 N + 1문제를 해결할 수 없다.
예를 들어 Users 테이블과 Articles 테이블이 있다고 하자.
Users

Articles

두 테이블을 조인하면

다음과 같은 테이블이 나온다.
여기서 "첫 2명의 유저"에 대한 페이징 요청을 한다면:
SELECT u.*, a.*
FROM users u
JOIN articles a ON u.id = a.user_id
LIMIT 2결과는 아래와 같다.
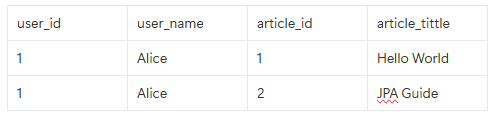
이 예시는 2가지 문제점을 시사한다:
- OneToMany 관계에서 조인을 하면 데이터가 중복된다. ➡️ 중복 데이터 때문에 페이징의 기준이 모호해진다.
- 인메모리 페이징 처리
Hibernate는 DB 레벨 페이징(LIMIT, OFFSET)을 적용하지 않고 모든 데이터를 메모리로 로드한 후 애플리케이션의 메모리내에 페이징을 수행한다. ➡️ Out of Memory가 발생할 위험이 있고, paging처리를 한 의미가 없다!
💡 Pagination의 Join fetch 문제점은 ToOne 관계에서는 발생하지 않는다.
ToOne 관계에서는 조인 시 결과 레코드 수가 증가하지 않아 데이터 중복이 없기 때문이다.
따라서 ToOne 관계에서는 Join fetch를 사용해도 괜찮다.
Pagination 해결책 : `@Batch Size`
ToMany 관계에서 Join fetch를 사용하면 하나의 "One" (or Many) 엔티티에 여러 "Many" 엔티티가 연결되어 데이터 중복이 발생한다. 따라서, 중복된 데이터로 어떠한 기준을 가지고 페이지를 나누기 어렵다.
ToMany 관계를 페이징 처리하기 위해선 `@BatchSize`를 사용하는 방법이 있다.
`@BatchSize`는 엔티티를 지연로딩하되, 지정한 크기만큼 한 번에 가져오는 방식으로 N + 1문제를 완화한다.
일반적인 지연 로딩에서는 post에 접근할 때마다 개별 쿼리가 발생한다:
-- 첫 번째 user의 article 접근 시
SELECT * FROM article WHERE user_id = 1
-- 두 번째 user의 article 접근 시
SELECT * FROM article WHERE user_id = 2
-- 이런 식으로 user 개수만큼 쿼리 발생 (N+1 문제)BatchSize를 적용하면 개별 쿼리 대신 `IN`절을 사용하여 여러 user의 article을 한 번에 가져온다:
-- 최대 100명의 user에 대한 article을 한 번에 조회
SELECT * FROM article WHERE user_id IN (1, 2, 3, ..., 100)BatchSize는 "조회할 엔티티의 개수"가 아닌 "한 번의 쿼리로 처리할 상위 엔티티(User)의 개수"를 의미한다.
너무 작은 BatchSize는 쿼리 수가 많아져 데이터베이스 부하와 네트워크 오버헤드가 증가하고, 너무 큰 BatchSize는 불필요한 데이터까지 조회하고, 한 쿼리의 실행 시간이 길어질 수 있어 적절한 값을 찾아야 한다. (일반적으로는 100~1000 사이의 값 권장)
BatchSize를 통해 N + 1를 N + (N/BatchSize)로 개선할 수 있다.
Pagination 해결책 1: `@Fetch(FetchMode.SUBSELECT)`
SUBSELECT는 기본 엔티티를 조회하고, 원본 쿼리를 서브쿼리로 사용해 관련 모든 컬렉션 항목을 한 번에 로드한다.
SELECT * FROM user LIMIT 10 OFFSET 0
SELECT * FROM article
WHERE user_id IN (
SELECT id FROM user WHERE ... (원본 쿼리와 동일 조건)
)
BatchSize와 다르게 SUBSELECT는 한 번의 쿼리로, 모든 범위의 데이터를 처리한다. `WHERE user_id IN (SELECT id FROM user WHERE ...)`라고 보면 될 것 같다.
하지만 SUBSELECT의 서브쿼리는 페이징 조건 ` SELECT * FROM user LIMIT 10 OFFSET 0` 을 포함하지 않는다. 10명의 User만 페이징하여 조회하려고 했지만, 서브쿼리를 실행할 때는 전체 User 테이블을 사용하기 때문에 대용량 데이터에서는 성능 이슈가 발생할 수 있다.
2. 둘 이상의 Collction Join fetch(~ToMany) 불가능
ToMany 관계를 Join fetch하면 데이터베이스에서 카테시안 곱이 발생해 데이터 복제가 너무 커진다. ➡️ 데이터 양이 너무 커 메모리가 부족할 수 있다.
Hibernate는 두 개 이상의 컬렉션을 즉시 로딩(Join fetch)하려고 할 때 `MultipleBagFetchException`를 발생시킨다.
여기서 해당 컬렉션은 순서가 있고 중복 요소를 허용한다. ➡️ JPA의 `List` 타입 컬렉션
💡 둘 이상의 Collction Join fetch을 하는 할 일이 있을까?
도메인 모델이 복잡해지거나, N + 1문제를 해결하기 위해 Join fetch를 사용하는데, 여러 컬렉션에 대해 Join fetch를 적용하려 할 수가 있다.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// List 타입(Bag)의 컬렉션 - 두 개의 OneToMany 관계
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Order> orders = new ArrayList<>();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Review> reviews = new ArrayList<>();
}
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
private String productName;
private BigDecimal price;
}
@Entity
@Table(name = "reviews")
public class Review {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
private String content;
private int rating;
}레포지토리에서 두 컬렉션을 동시에 Join fetch하려고 시도하면
public interface UserRepository extends JpaRepository<User, Long> {
// 문제가 되는 쿼리: 두 개의 컬렉션을 동시에 페치 조인
@Query("SELECT DISTINCT u FROM User u " +
"LEFT JOIN FETCH u.orders " +
"LEFT JOIN FETCH u.reviews")
List<User> findAllWithOrdersAndReviews();
// 또는 EntityGraph를 사용한 방식
@EntityGraph(attributePaths = {"orders", "reviews"})
List<User> findAll();
}
// 예외 발생
// org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [com.example.demo.User.orders, com.example.demo.User.reviews]Hibernate에서 의도적으로 잠재적인 성능 및 메모리 문제를 방지하기 위해 인 메모리에서 ToMany 관계를 Join fetch할 때 exception을 발생시킨다.
MultipleBagFetchException 대안책 : 컬렉션을 Set으로 변경
`Set`은 중복을 허용하지 않는다. 따라서, `List`로 선언했을 때 발생하는 데이터 중복을 해결할 수 있다.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// Set으로 컬렉션 타입 변경
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Order> orders = new LinkedHashSet<>();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Review> reviews = new LinkedHashSet<>();
}`Set`에 담긴 데이터의 순서가 중요한 경우는 `LinkedHashset`을 사용하고, 순서를 보장하지 않아도 된다면 `HashSet`을 사용할 수 있다.
하지만 `LinkedHashset`는 `List`보다 많은 메모리를 사용하기 때문에 ` MultipleBagFetchException`를 피하기 위한 트레이드 오프로 볼 수 있다.
Set을 사용해 paging을 요청해도, 컬렉션 Join fetch 때문에 paging은 메모리에서 처리된다. 따라서, OOM을 발생시킬 수 있기 때문에 해결책이 아닌 대안책이다.
MultipleBagFetchException 해결책 : `@BatchSize`
JPA에서 컬렉션 Join fetch를 사용하면서 인메모리 로딩을 막을 수 없다. (Hibernate의 설계 방식 때문에)
`@BatchSize`를 사용하면 인메모리 로딩 이슈를 피할 수 있다.
@Entity
public class User {
@Id
private Long id;
private String name;
@BatchSize(size = 30) // 배치 사이즈 설정
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Order> orders = new ArrayList<>();
@BatchSize(size = 30) // 배치 사이즈 설정
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Review> reviews = new ArrayList<>();
}@Service
@Transactional(readOnly = true) // 읽기 전용 트랜잭션으로 메모리 최적화
public class UserService {
private final UserRepository userRepository;
// 페이징을 사용하면서 배치 로딩 활용
public Page<User> getUsersWithOrdersAndReviews(Pageable pageable) {
// 1. User만 페이징하여 가져옴 (컬렉션 fetch join 없음)
Page<User> users = userRepository.findAll(pageable);
// 2. 지연 로딩 초기화 (배치 로딩 적용됨)
users.getContent().forEach(user -> {
user.getOrders().size(); // 지연 로딩 초기화 (배치 로딩으로 최적화)
user.getReviews().size(); // 지연 로딩 초기화 (배치 로딩으로 최적화)
});
return users;
}
}- `findAll(pageable)`로 User 엔티티만 페이징하여 가져온다.
- `user.getOrders().size()`를 호출하면 지연 로딩이 발생하지만, `IN`절을 사용하여 한 번에 여러 User의 orders를 가져온다.
- `user.getReviews().size()`도 마찬가지로 배치 로딩이 적용된다.
`@BatchSize`는 부모 엔티티를 먼저 가져오고(부모 엔티티 중복 X), BatchSize 크기만큼 부모 ID를 포함하는 `IN`절을 사용해 (부모 ID 개수 / BatchSize)만큼 조회한다.
`@BatchSize`에 Join fetch를 걸면 안된다. Join fetch는 `@BatchSize`보다 우선순위가 높기 때문에 원하는대로 작동하지 않는다.
ToOne 관계에서는 Join fetch를 사용하고, ToMany 컬렉션에서는 `@BatchSize`를 사용하자.
References
JPA 모든 N+1 발생 케이스과 해결책
N+1이 발생하는 모든 케이스 (즉시로딩, 지연로딩)에서의 해결책과 그 해결책에서의 문제를 해결하는 방법에 대해 이야기 하려합니다 😀
velog.io
https://tecoble.techcourse.co.kr/post/2021-07-26-jpa-pageable/
JPA Pagination, 그리고 N + 1 문제
1. Pagination 게시판 기능을 제공하는 웹 어플리케이션에 접속하여 게시물 목록을 요청하는 경우를 상상해봅시다. DB…
tecoble.techcourse.co.kr
'Spring > Spring Data JPA' 카테고리의 다른 글
| [Spring Data JPA] @OneToOne 연관관계에서 Lazy Loading이 동작하지 않는 경우 (2) | 2025.07.11 |
|---|---|
| [Spring Data JPA] ID에 관하여 (2) | 2025.03.13 |
| [Spring Data JPA] 엔티티 매니저(Entity Manager) (0) | 2025.03.05 |
| [Spring Data JPA] 영속성 컨텍스트(Persistence Context) (0) | 2025.03.04 |
| [Spring Data JPA] JPA의 ddl-auto 옵션 (0) | 2025.02.28 |